Advanced techniques of video coding
Motivation
It is well known that streaming videos across Mobile Ad hoc Networks (MANETs) introduces a lot of challenges. The own definition of MANET, which entails wireless links, multi hop routes and mobility of nodes, is the main reason of the biggest problems: a considerable reduction of the available bandwidth and a dynamic topology with frequent route breakages. All this causes packet loss and negative effects in traffic throughput.
Different solutions have been proposed to overcome these challenges in MANET networks, some of them based on cross-layer mechanisms, enhancements to MAC layer or new routing protocols designed to consider node disconnections and power consumption efficiency. Moreover, another roadmap would involve the inclusion of a static backbone, like in Wireless Mesh Networks (WMN), by reducing the mobility of some router nodes. In addition, some solutions have been proposed at application layer, from loss differentiation algorithms, which allow applications to adapt to the type of losses (congestion, route breakage, etc.), to new video coding techniques, such as Layered Coding (LC) [1] or Multiple Description Coding (MDC) [2]. MDC is a video coding technique capable of enhancing error resilience of a video delivery system by means of providing multiple video flows with redundant and improving information. This encoding technique is specially useful in multipoint-to-point transmissions due to the disjuntion of packet routes. This scheme makes packet losses more independent and increases the packet delivery probability. Among other solutions, MDC appears as one of the most suitable solution in multi-hop networks due to the possibility of using disjoint paths towards destination.
Another interesting mechanism used to minimize the burst effect and the unpredictability of packet losses is the Forward Error Correction (FEC) mechanism [3]. This technique consists of adding redundant data to the previously compressed signal, which allows the receiver to correct some errors without the need for any retransmission. However, this redundancy increases the total amount of bits required to transmit a specific content and, consequently, compression efficiency is reduced.
Overview
There are several procedures for generating descriptions. Usually, a source video stream is divided into different groups or substreams. These substreams are encoded separately and used as individual descriptions in the system. Some other methods use interdependent descriptions with correlated information to improve compression efficiency [4]. Segmentation of video sequence can be carried out in temporal, spatial or frequency domain. Figure 1 depicts how the decoding process would be in a real video sequence using SDC and temporal MDC with two descriptions when frame losses occur. In the figure a temporal domain multidescription is shown. From original raw video sequence, symbol O represents a frame correctly received and symbol X means that the frame is lost or not fully decoded. In SDC, the video flow is interrupted and luckily, most players might freeze or repeat the last decoded frame (otherwise, a black screen is displayed instead). On the other hand, when some frames from one description are lost, MDC replicates the last frame correctly received from the other description, resulting in a video stream with half frame rate but with neither interruptions nor artifacts and, therefore, the overall experienced quality is improved. If losses occur in every description at the same time, no video reconstruction is obviously possible. Thus, the descriptions must be sent through disjoint paths to try to make losses independent in each description.
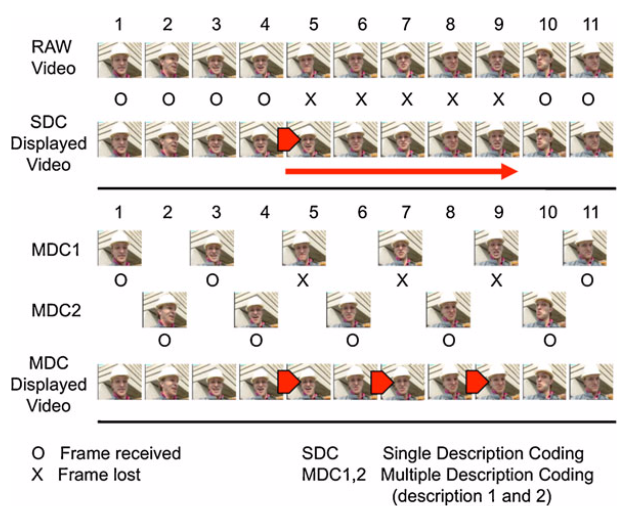
Figure 1. Decoding with SDC and MDC when frame losses occur
It is worth noting that by encoding each substream independently, the overall required bandwidth for multidescription transmissions is greater than the one required for SDC. This drawback is due to the fact that the substreams are generated from non-consecutive frames causing lower compression efficiency. The more dynamic the video sequence, the bigger the mean frame size. Moreover, FEC also introduces traffic overhead, so this is another issue that must betaken into consideration. The degree of protection provided by FEC depends on the amount of redundancy added to the information to be transmitted. The higher the percentage of redundancy, the better the resistance against losses. However, this entails adding more traffic to the network.
The FEC encoding scheme is based on block coding, i.e. data packets are grouped into blocks designated by (n, k),where k is the number of video packets to protect and n is the total amount of packets generated. Therefore, n-k packets are generated with FEC information from the k video packets that form the block. These FEC packets must be generated from linearly independent combinations of data packets and, ideally, data packets can be fully recovered if and only if any k packets from the block are received at least. In addition, as long as FEC operates in a block of packets, this block size directly affects the ability to correct mistakes related to burst losses, resulting in the loss of multiple consecutive packets. This is an important point because in ad hoc networks losses often occur in bursts, so the FEC algorithm must be resistant to this kind of losses. For the same FEC level, better results are obtained (i.e. higher number of packets are recovered) by using a large block size. However, it is worth noting that the block size directly influences the video playing delay, since the receiver has to wait for a complete video block to rebuild and play the video. This also implies that the receiver must have a buffer with enough capacity to store all packets in the block, i.e. video packets plus FEC packets. Hence, rendering delay is directly related to the block size, because when some video packets are lost, the receiver has to wait for FEC packets, which are sent after the entire video block.
The streaming service proposed, which is based on MDC and FEC, works as shown in Figure 2. A raw video in YUV format is encoded into two descriptions. This is achieved by splitting the original video frames in subsets depending on their time position. Therefore, the raw video is separated into two descriptions with a frame rate half of the original frame rate. So, the video content is encoded in several descriptions so they can be sent separately. The streaming server sends video description and FEC flows to the node that requests them. Access nodes are ad hoc nodes connected to the content server through a wired network. Unlike the other nodes, access nodes have two interfaces in order to retransmit packets from the server in the wired network to the wireless nodes in the ad hoc network. Wireless nodes arbitrarily move within a delimited coverage zone. Any node in the network can request a video from the server so the routing protocol has to ensure that video and FEC packets are delivered to the destination node. Devices not involved in any communication can act as routers for the traffic of other connections. The routing protocol used is OLSR (Optimized Link State Routing) [5].
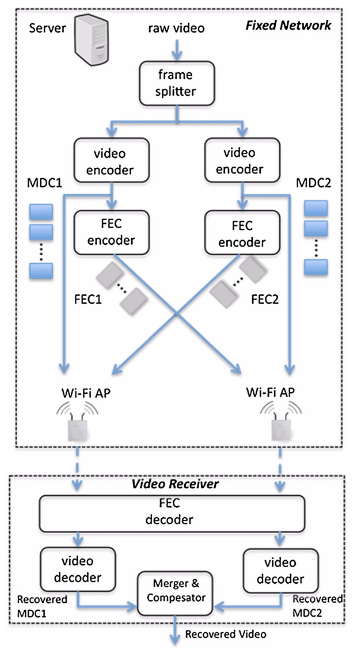
Figure 2. Streaming service workflow
When any device requests a video stream, the content server transmits the video descriptions and FEC flows through the access points. Each description is sent and transmitted through a different access point using static routing configuration. Additionally, the corresponding FEC flow for each description is transmitted through the opposite access point, i.e. description and FEC are also sent through disjoint paths. When video and FEC packets arrive to the access point, it retransmits them to the wireless network. If the requesting node is not in range, intermediate nodes behave as routers. Access points are placed at opposite edges in the scenario so descriptions and FEC flows can be transmitted over likely disjoint paths and no routing protocol modification is needed. As a good consequence of using MDC, mobile devices with limited processing capabilities could request only one description in order to play the stream at a lower rate. Moreover, devices with constrained bandwidth could also avoid congestion with this method.
Some of the publications of the research group related to this field are shown in [6]-[12].
References
[1] H. Schwarz, D. Marpe, and T. Wiegand, “Overview of the scalable video coding extension of the H.264/AVC standard,” IEEE Trans Circ Syst Video Tech, vol. 17, pp. 1103-1120, 2007.
[2] J. G. Apostolopoulos, T. Wong, W. Tan, and S. J. Wee, “On multiple description streaming with content delivery networks,” IEEE INFOCOM, 2002.
[3] Y. Xunqi, J. W. Modestino, I. V. Bajic, “Performance analysis of the efficacy of packet-level FEC in improving video transport over networks,” IEEE International Conference on Image Processing, vol. 2, pp. 177-180, 2005.
[4] S. Mao et al., “Video transport over ad hoc networks: multistream coding with multipath transport,” IEEE J. Sel Area Comm, vol. 21, pp. 1721-1737, 2003.
[5] T. Clausen and P. Jacquet, “Optimized link state routing protocol (OLSR),” IETF vol. RFC 3626, 2003.
Related publications
[6] P. Acelas, P. Arce, and J. C. Guerri, “Effect of the multiple description coding over a Hybrid Fixed-AdHoc Video Distribution Network,” in 2nd International Workshop on Future Multimedia Networking, Coimbra (Portugal), Jun. 2009.
[7] J. C. Guerri, P. Arce, and P. Acelas, “Mechanisms for improving video streaming in mobile ad hoc networks,” Waves 2009 (iTEAM UPV Journal), vol. 1, pp. 24-34, 2009.
[8] W. Castellanos, P. Acelas, P. Arce, and J. C. Guerri, “Evaluation of a QoS-Aware Protocol with Adaptive Feedback Scheme for Mobile Ad Hoc Networks,” in Proc. of the Int. ICST Conference on Heterogeneous Networking for Quality, Reliability, Security and Robustness (QSHINE), Las Palmas (Spain), Nov. 2009, pp. 120-127.
[9] P. Acelas, P. Arce, W. Castellanos, and J. C. Guerri, “Estudio sobre el Efecto de la Codificación de Vídeo por Multidescripción en Redes MANET,” XV Simposium Nacional de la Unión Científica Internacional de Radio (URSI 2010), Bilbao (Spain), Sep. 2010.
[10] J. C. Guerri, P. Arce, P. Acelas, W. Castellanos, and F. Fraile, “Routing and Coding Enhancements to Improve QoS of Video Transmissions in Future Ad Hoc Networks,” Multimedia Services and Streaming for Mobile Devices: Challenges and Innovations, Ed. IGI Global, pp. 244-261, 2011.
[11] P. Guzmán, P. Acelas, T. R. Vargas, P. Arce, J. C. Guerri, E. Macías, and A. Suárez, “QoE evaluation and adaptive transport for 3D mobile services,” presented at the 2nd Workshop on Future Internet: Efficiency in High-Speed Networks (W-FIERRO), Cartagena, Murcia, Spain, Jul. 2012.
[12] P. Acelas, P. Arce, J. C. Guerri, and W. Castellanos, “Evaluation of the MDC and FEC over the quality of service and quality of experience for video distribution in ad hoc networks,” Multimedia Tools and Applications, vol. 68. no. 3, pp. 969-989, 2014.